Flink问题整理
问题1:bin/config.sh: line 32: syntax error near unexpected token
执行 sh start-cluster.sh脚本启动集群,报错:
/xxx/bin/config.sh:行32: syntax error near unexpected token `(`
/xxx/bin/config.sh:行32: ` done << (find "$FLINK_LIB_DIR" ! -type d -name '*.jar' -print0 | sort -z)'
解决
不要使用sh来启动,使用 bash start-cluster.sh 或 ./start-cluster.sh来启动。
这是因为start-cluster.sh文件中有sh不支持的语法。下面说明下bash和sh的区别:
bash是sh的增强版,sh全称是Bourne Shell,bash全称是Bourne Again Shell,linux系统默认使用的就是bash的posix模式。可以查看 echo $SHELL。值为/bin/bash。虽然sh是个软连接,指向了bash,但是还是有区别的,sh执行的相当于bash -posix xxx.sh,也就是说xxx.sh脚本必须遵守posix的规则,如果不然就会报错。
shell script一般第一行指定解释器,所以还是指定#!/bin/bash好,不要再用#!/bin/sh了。
sh是一个shell。运行sh a.sh,表示我使用sh来解释这个脚本;如果我直接运行./a.sh,首先你会查找脚本第一行是否指定了解释器,如果没指定,那么就用当前系统默认的shell(大多数linux默认是bash),如果指定了解释器,那么就将该脚本交给指定的解释器。
问题2:执行./stop-cluster.sh 关闭集群,报
No taskexecutor daemon to stop on host xxx
No standalonesession daemon to stop on host xxx
解决
在flink的安装目录下的 /bin 目录下有个 config.sh 脚本文件,里面有一项配置用来配置flink服务的pid文件目录,配置名称为: DEFAULT_ENV_PID_DIR ,默认值为 /tmp 。而由于/tmp 会被系统定期清理,所以存放的ID就找不到了,也就没法关闭集群了。所以这里最好修改为flink集群安装的位置下再加个目录 pids 即可。
问题3:Unexpected error in InitProducerIdResponse; The transaction timeout is larger than the maximum value allowed by the broker (as configured by transaction.max.timeout.ms).
解决
当FlinkKafkaProducer.Semantic指定为FlinkKafkaProducer.Semantic.AT_LEAST_ONCE时,执行没有问题。
当FlinkKafkaProducer.Semantic指定为FlinkKafkaProducer.Semantic.EXACTLY_ONCE时,执行报上面的错误。
官网关于Kafka Producers and Fault Tolerance有一段说明
Kafka brokers by default have transaction.max.timeout.ms set to 15 minutes.
This property will not allow to set transaction timeouts for the producers larger than it’s value.
FlinkKafkaProducer011 by default sets the transaction.timeout.ms property in producer config to 1 hour, thus transaction.max.timeout.ms should be increased before using the Semantic.EXACTLY_ONCE mode.
Kafka brokers 默认的最大事务超时(transaction.max.timeout.ms)为15 minutes,生产者设置事务超时不允许大于这个值。所以在使用EXACTLY_ONCE语义的时候需要改小transaction.max.timeout.ms的值,
kafkaPro.setProperty("transaction.timeout.ms",1000*60*10+"")
问题4:org.apache.flink.table.api.ValidationException: Could not find any factory for identifier ‘jdbc’ that implements ‘org.apache.flink.table.factories.DynamicTableFactory’ in the classpath.
解决:
缺少flink-connector-jdbc_xxx.jar,下载放置到lib下
问题5:Flink InvalidTypesException: The return type of function could not be determined automatically…
解决:
大致意思是,lambda写法无法提供足够的类型信息,无法推断出正确的类型,建议要么改成匿名类写法,要么用type information提供明细的类型信息。我们可以在转换的算子之后调用returns(…)方法来显示指明要返回的数据类型信息。
比如:
map((MapFunction<String, Tuple2<String, Integer>>) filterRecord -> {
return new Tuple2(filterRecord, 1);
}).returns(Types.TUPLE(Types.STRING, Types.INT))
问题6:在idea环境中,执行env.execute()启动flink以后,发现程序似乎运行着,但一直卡着
解决:
很可能是报错了,但是由于StreamExecutionEnvironment本身的重启策略是固定延迟但是不限重启次数的策略,所以错误才会一直无法报出来。可以先设置不重启策略来看下。
env.setRestartStrategy(RestartStrategies.noRestart());
问题7:Flink SQL 创建 TableEnvironment 对象失败
现象:
No factory implements 'org.apache.flink.table.delegation.ExecutorFactory'
解决:
除了引入:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
以外,还需要引入:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
问题8:Table sink doesn’t support consuming update changes which is produced
将Table转化为DataStream的时候,调用了api:toDataStream或toAppendStream,这是因为sql里些了比如 count(xxx) group by 这种形成的不是append stream,所以无法转化,需要使用toChangelogStream或toRetractStream
问题9:Exception in thread “Thread-6” java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields
这是一个hadoop3和flink导致的一个bug,详见:
https://issues.apache.org/jira/browse/FLINK-19916
这并不影响当前功能,所以可以先不用关注。
问题10:IF(condition,true_value,false_value)时使用null,报错org.apache.calcite.sql.validate.SqlValidatorException: Illegal use of ‘NULL’
比如:IF(5>3,‘12321’,NULL),这时会报错可以写成IF(5>3,‘12321’,cast(NULL as STRING))
问题11:flink-oracle-cdc,获取变更数据时,number类型的数据乱码,
解决
增加配置 decimal.handling.mode = String

问题12:flink-oracle-cdc 用flinksql获取sourcetable时,获取不到变更数据,DataException: file is not a valid field name,改用datastream api
解决
把debezium的配置去掉
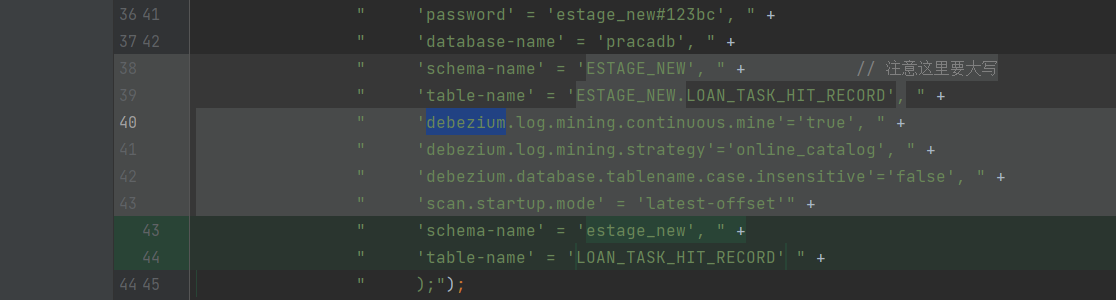
问题13: lookup join table, 当变更数据流进来关联维表时,除初始化话读取的维表数据外,没有去查询维表数据
解决
- 维表构建时需要定义主键
- 关联时需要指定处理时间或者事件时间
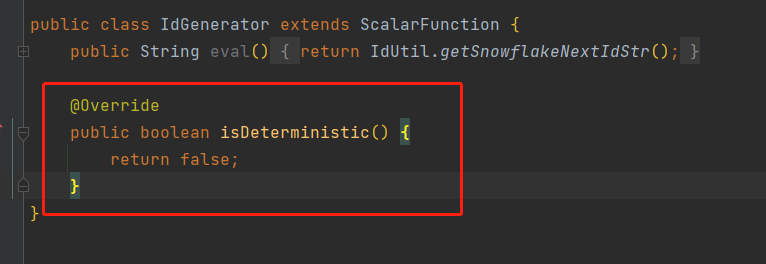
问题14:自定义udf时,计算数据总是固定的,比如我定义一个主键id生成的函数,id没有变化,
解决
下图红框是关键,表示每次重新计算,即返回值不固定
问题15:一个main方法里同时写有datastreamapi和tableapi的代码时,用flink webui 提交作业,Cannot have more than one execute() or executeAsync() call in a single environment.
解决
- 改用flink run 命令行提交作业,其中一个flinksql的insert语句会单独生成一个作业, 有多个insert语句可以用StreamStatementSet来批量提交。
再次更新这个问题,原来报错不是简单因为datastream api的代码,是有多个execute执行了。

最终解决:去掉env.execute(); 把多个insert语句使用statementSet合并为一个。这样就是一个job了,无论是webui提交还是命令行提交都不会有问题了。
造成不同提交方式的差异是因为enforceSingleJobExecution这个参数的问题,命令行执行程序使用的是CliFrontend::executeProgram,enforceSingleJobExecution参数默认为false
protected void executeProgram(final Configuration configuration, final PackagedProgram program)
throws ProgramInvocationException {
ClientUtils.executeProgram(
new DefaultExecutorServiceLoader(), configuration, program, false, false);
}
问题16: flink oracle cdc 启动报错,任务关闭

解决:
flink oracle cdc 在读取全量快照数据时是无法执行checkpoint的
把checkpoint的超时时间设长一些,直到快照数据读取完毕就行了
// Can’t perform checkpoint during scanning snapshot of tables
env.getCheckpointConfig().setCheckpointInterval(10 * 60 * 1000L);
env.getCheckpointConfig().setCheckpointTimeout(5 * 60 * 1000L);
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);
问题17:
JdbcSink.exactlyOnceSink
OracleXADataSource 报错

解决:
赋予oracle 用户如下权限:
grant SELECT ANY DICTIONARY to dbuser;
grant ALTER SESSION to dbuser;
问题18:报错:Task did not exit gracefully within 180 + seconds.
报错详情
Task did not exit gracefully within 180 + seconds.
2022-04-22T17:32:25.852861506+08:00 stdout F org.apache.flink.util.FlinkRuntimeException: Task did not exit gracefully within 180 + seconds.
2022-04-22T17:32:25.852865065+08:00 stdout F at org.apache.flink.runtime.taskmanager.Task$TaskCancelerWatchDog.run(Task.java:1709) [flink-dist_2.11-1.12-vvr-3.0.4-SNAPSHOT.jar:1.12-vvr-3.0.4-SNAPSHOT]
2022-04-22T17:32:25.852867996+08:00 stdout F at java.lang.Thread.run(Thread.java:834) [?:1.8.0_102]
log_level:ERROR
报错原因
该报错不是作业异常的根因。因为Task退出的超时task.cancellation.timeout参数的默认值为180s,当作业Failover或退出过程中,可能会因某种原因阻塞Task的退出。当阻塞时间达到超时时间后,Flink会判定该Task已卡死无法恢复,会主动停止该Task所在的TaskManager,让Failover或退出流程继续下去,所以在日志中会出现这样的报错。
真正的原因可能是您自定义函数的实现有问题,例如close方法的实现中长时间阻塞或者计算方法长时间未返回等。
解决方案
设置Task退出的超时时间参数task.cancellation.timeout取值为0。配置为0时,Task退出阻塞将不会超时,该task会持续等待退出完成。重启作业后再次发现作业在Failover或退出过程中长时间阻塞时,需要找到处于Cancelling状态的Task,查看该Task的栈,排查问题的根因,然后根据排查到的根因再针对性解决问题。
说明 task.cancellation.timeout参数用于作业调试,请不要在生产作业上配置该参数值为0。
问题19 报错:Job was submitted in detached mode. Results of job execution, such as accumulators, runtime, etc. are not available.
报错详情
Caused by: org.apache.flink.api.common.InvalidProgramException: Job was submitted in detached mode. Results of job execution, such as accumulators, runtime, etc. are not available. Please make sure your program doesn’t call an eager execution function [collect, print, printToErr, count].
报错原因
Flink作业有Detached和Blocking两种提交模式:
Detached是指通过客户端、Java API或RESTful等方式提交的,提交后无法看到作业的运行结果,需通过日志查看作业运行情况,类似于异步回调。
Blocking是指在IDEA或者其他方式直接启动的,可以通过关闭终端或Ctrl+C的方式直接关闭正在运行的Flink作业。
当Flink作业以Detached模式提交时,不能以Collect、Print、PrintToErr或Count等Operator做结尾;当作业以Blocking模式提交时,没有这些限制。
解决方案
使用SQL作业运行。
TableAPI JAR作业不要以Collect、Print、PrintToErr或Count等Operator做结尾。
问题20:flink web ui 上传的jar包去哪了,重启之后就不见了?
解决:
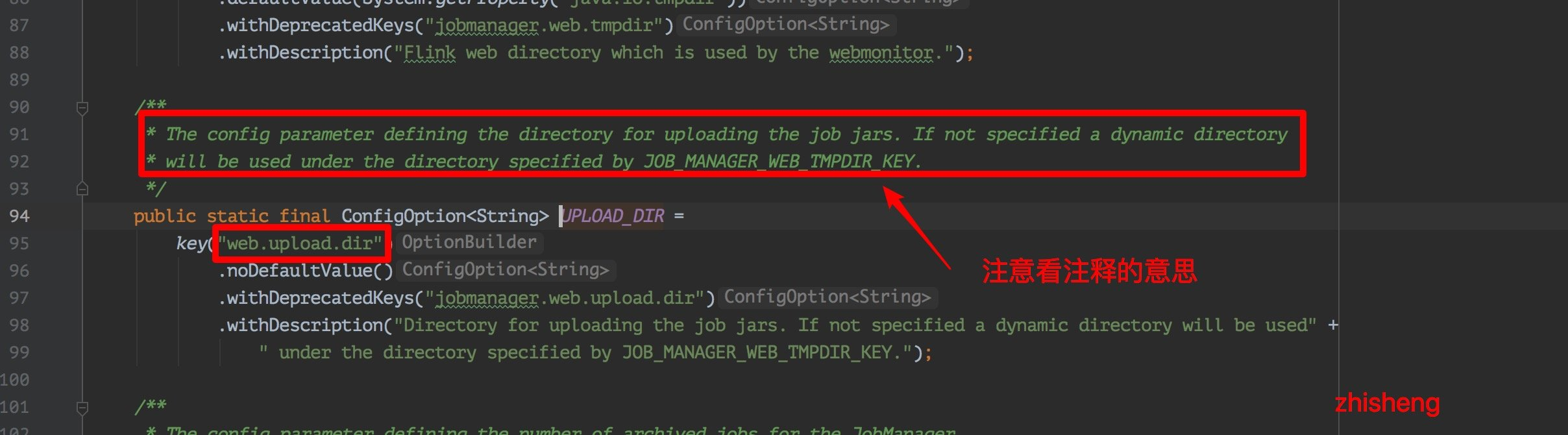
如果这个配置 web.upload.dir 没有配置具体的路径的话就会使用 JOB_MANAGER_WEB_TMPDIR_KEY 目录
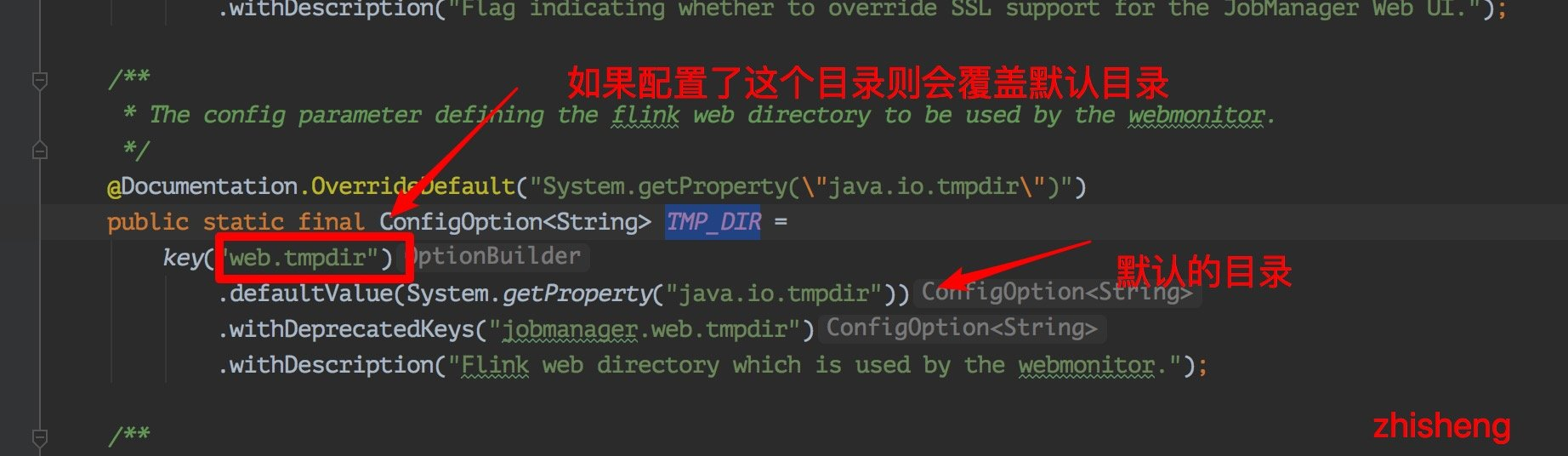
发现 jobManager 这里有个 web.tmpdir 的配置:
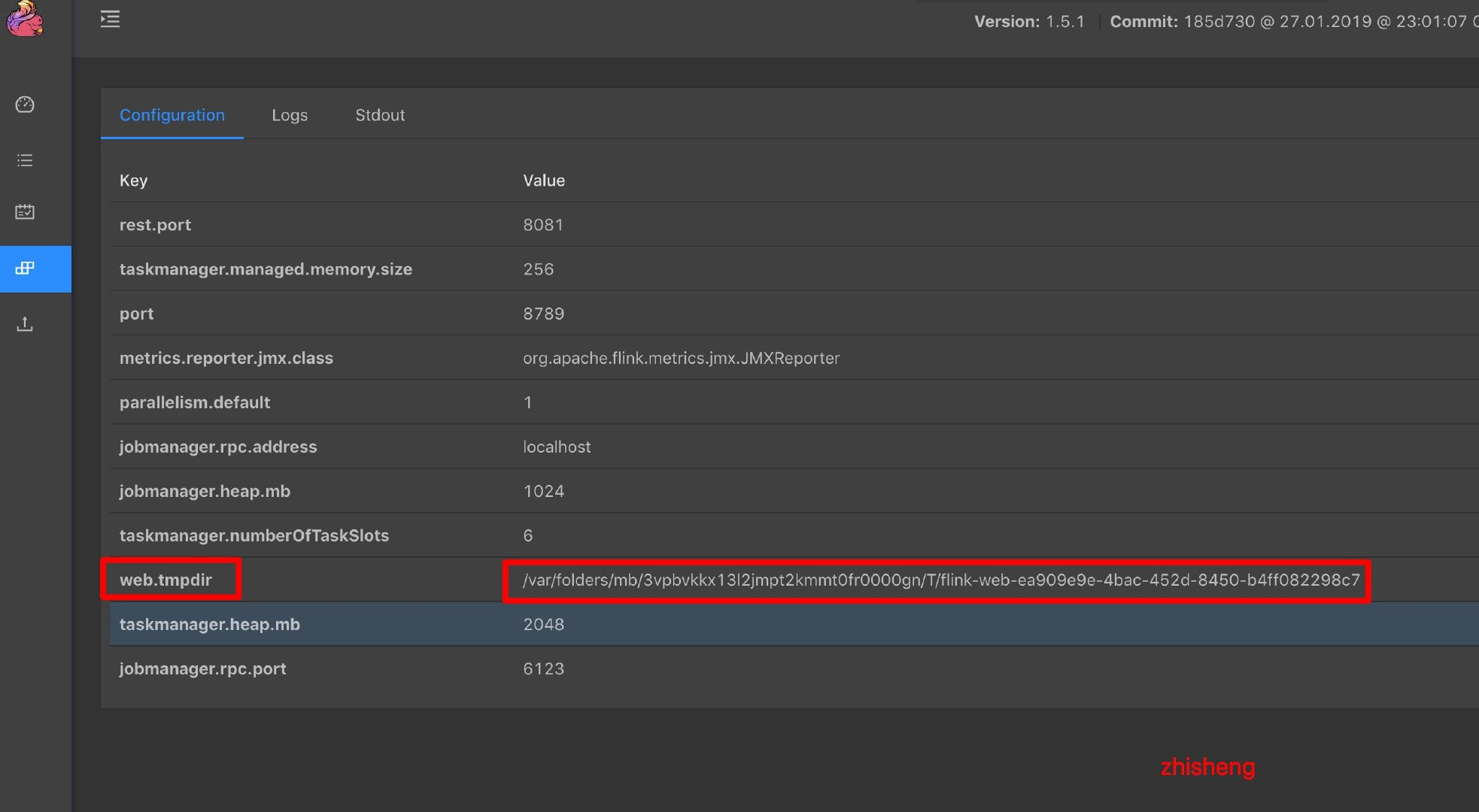
发现这个 web.tmpdir 的就是由 java.io.tmpdir + “flink-web-” + UUID 组成的!
结论:
web.tmpdir 可以配置jar上传的临时目录,重启就会被删除
web.upload.dir: 可以配置一个固定的目录,flink重启也不会删除
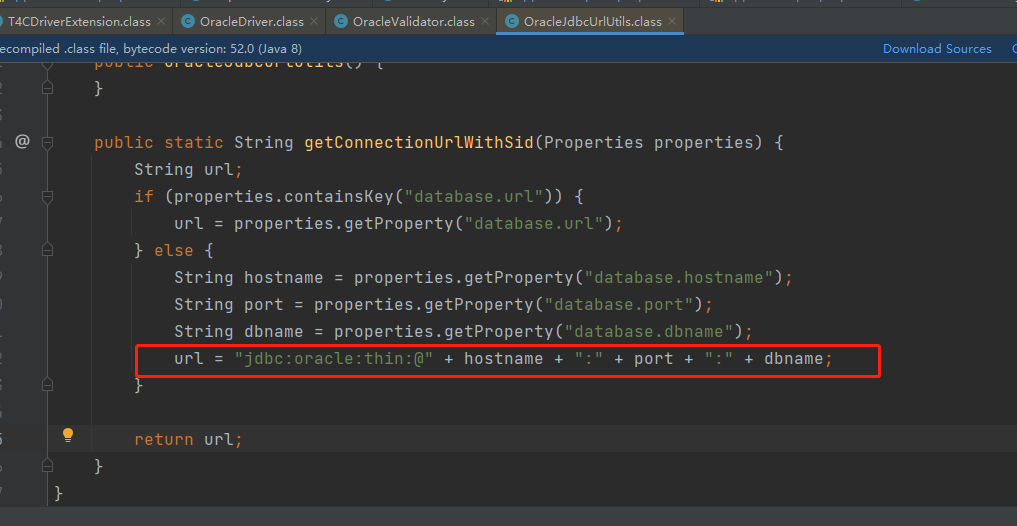
问题21:flink oracle cdc connector
报错:
oracle.net.ns.NetException: Listener refused the connection with the following error:
ORA-12505, TNS:listener does not currently know of SID given in connect descriptor
解决1:OracleSource配置中的database填的是服务名,要填sid
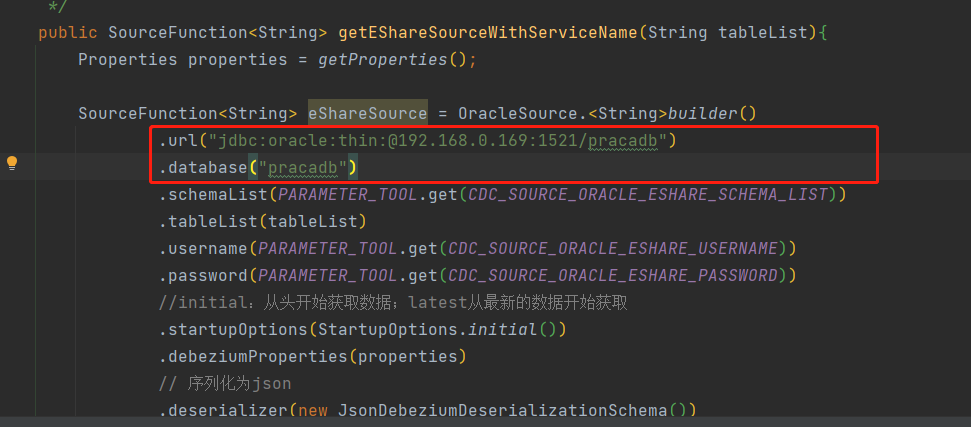
解决2:用url代替
问题22: flink oracle cdc 用flinksql实现时报错:
The db history topic or its content is fully or partially missing. Please check database history topic configuration and re-execute the snapshot.
解决:
检查要监控的表名有没有写错,并且表名前面是不需要加schema的,但是datastreamApi一定要加; 坑。。。。
问题23:flink oracle cdc 用一个用户去同步另外一个用户的表时,报权限不足
解决
给用户赋上官方推荐的权限,同时注意lock权限,
GRANT CREATE SESSION TO flinkuser;
GRANT SET CONTAINER TO flinkuser;
GRANT SELECT ON V_$DATABASE to flinkuser;
GRANT FLASHBACK ANY TABLE TO flinkuser;
GRANT SELECT ANY TABLE TO flinkuser;
GRANT SELECT_CATALOG_ROLE TO flinkuser;
GRANT EXECUTE_CATALOG_ROLE TO flinkuser;
GRANT SELECT ANY TRANSACTION TO flinkuser;
GRANT LOGMINING TO flinkuser;
GRANT CREATE TABLE TO flinkuser;
-- need not to execute if set scan.incremental.snapshot.enabled=true(default)
GRANT LOCK ANY TABLE TO flinkuser;
GRANT ALTER ANY TABLE TO flinkuser;
GRANT CREATE SEQUENCE TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser;
GRANT SELECT ON V_$LOG TO flinkuser;
GRANT SELECT ON V_$LOG_HISTORY TO flinkuser;
GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser;
GRANT SELECT ON V_$LOGFILE TO flinkuser;
GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser;
2.3以后Oracle CDC 连接器都对接到了 Flink CDC 增量快照框架上,实现了增量快照算法,从而提供无锁读取,并行读取和断点续传的功能。
但是值得注意的是 实际使用测试结果: datastreamApi 写flinkcdc同步oracle数据库时还是会对表加row share mode 锁,但是用flinksql写是可以的;不知道2.4版本会不会解决这个问题
问题24:
org.apache.flink.runtime.checkpoint.CheckpointException: Could not complete snapshot 1 for operator SinkMaterializer[34] -> Sink: DWD_MV_MODEL_RESULT[34] (1/1)#0. Failure reason: Checkpoint was declined.
Caused by: org.apache.flink.util.SerializedThrowable: org.apache.flink.runtime.checkpoint.CheckpointException: Could not complete snapshot 1 for operator SinkMaterializer[34] -> Sink: DWD_MV_MODEL_RESULT[34] (1/1)#0. Failure reason: Checkpoint was declined.
Caused by: org.apache.flink.util.SerializedThrowable: org.rocksdb.RocksDBException: Failed to create a NewWriteableFile: C:\Users\ADMINI~1\AppData\Local\Temp\minicluster_90d8e1fae42ef71fa23b96a70b93499a\tm_0\tmp\job_69bb7fe81b92037ff577ea459210e4b1_op_SinkUpsertMaterializer_c70ed14757b4f4ce5dcc0caa758a081b__1_1__uuid_1fd9d570-cacf-4f90-bb29-cfdd814ef7f2\chk-1.tmp/MANIFEST-000004: ϵͳÕҲ»µ½ָ¶
原因: 检查点状态较大,超时导致的
解决
env.getCheckpointConfig().setCheckpointInterval(10 * 60 * 1000L);
env.getCheckpointConfig().setCheckpointTimeout(5 * 60 * 1000L);
更新
实际未解决,时间调大了后,只是当时没报错,后面也继续报错了,咋办呢 qaq
问题25
现象:flink row 类型在使用时,我这里先用upsertTable转changelogStream,然后用process处理后返回row类型的changelogStream,然后再转table, 这时打印table发现只有f0一个字段,字段类型被擦除了
解决:
在算子处理后添加类型提示信息,用Types.ROW_NAMED
DataStream<Row> kafkaRows = kafkaEvents
.map(new MyKafkaRecordToRowMapper())
.returns(Types.ROW_NAMED(
new String[] {"id", "quota", "ts", ...},
Types.STRING,
Types.LONG,
TypeInformation.of(Instant.class)),
...);
row类型介绍:Flink 中还定义了一个在关系型表中更加通用的数据类型——行(Row),它是 Table 中数据的基本组织形式。Row 类型也是一种复合类型,它的长度固定,而且无法直接推断出每个字段的类型,所以在使用时必须指明具体的类型信息;我们在创建 Table 时调用的 CREATE
语句就会将所有的字段名称和类型指定,这在 Flink 中被称为表的“模式结构”(Schema)。除 此之外,Row 类型还附加了一个属性 RowKind,用来表示当前行在更新操作中的类型。这样,Row 就可以用来表示更新日志流(changelog stream)中的数据,从而架起了 Flink 中流和表的 转换桥梁。
所以在更新日志流中,元素的类型必须是 Row,而且需要调用 ofKind()方法来指定更新类型。
问题26
flink jdbc sink 到oltp的数据库时发生死锁,
原因: 多并行度或者多任务往同一张表进行upsert时,发生死锁异常。一个是jdbcsink是批量提交的,一个是数据本身是乱序的,导致数据库不同session中互相持有对方需要的资源,并且不能释放,最终导致deadlock,;
解决:
主要是利用分布式锁,在执行sink前先判断有没有锁;
我之前是用flink sql 写的sink的代码,如果要jdbcsinkfunction就得改源码,不想改源码,所以目前采用datastreamAPI,重写了jdbcsinkfunction;
实现代码如下:
package cn.hrfax.common.function;
import cn.hrfax.config.utils.JedisUtil;
import cn.hutool.core.util.IdUtil;
import cn.hutool.core.util.StrUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.connector.jdbc.internal.GenericJdbcSinkFunction;
import org.apache.flink.connector.jdbc.internal.JdbcOutputFormat;
import org.apache.flink.types.Row;
import redis.clients.jedis.Jedis;
import java.io.IOException;
import java.util.Collections;
@Slf4j
public class LocksJdbcSinkFunction extends GenericJdbcSinkFunction<Row> {
public LocksJdbcSinkFunction(JdbcOutputFormat outputFormat) {
super(outputFormat);
}
/**
* 基于redis分布式锁的实现,解决多并行度、多任务的情况下,jdbc sink 死锁的问题
* value 数据进来,以position为0位置的数据作为分布式锁的key
*
* @param value The input record.
* @param context Additional context about the input record.
* @throws IOException
*/
@Override
public void invoke(Row value, Context context) throws IOException {
try {
// log.info("--rowkind:{}---value:{}", value.getKind(), value);
Object idField = value.getField(0);
if (idField != null && StrUtil.isNotBlank(idField.toString())) {
String key = idField.toString();
Jedis jedis = JedisUtil.getJedis();
String randomValue = IdUtil.getSnowflakeNextIdStr();
if (("OK").equals(jedis.set(key, randomValue, "NX", "EX", 10))) {
try {
super.invoke(value, context);
} catch (Exception e) {
log.info("--jdbcSink异常1---:{}", value);
log.error(e.getMessage(), e);
} finally {
// 避免其他线程删除锁
// if (randomValue.equals(jedis.get(key))) {
// jedis.del(key);
// }
// 非原子操作,改成lua脚本
String luaScript =
"if redis.call('get',KEYS[1]) == ARGV[1] then " +
" return redis.call('del',KEYS[1]) " +
"else " +
" return 0 " +
"end; ";
jedis.eval(luaScript, Collections.singletonList(key), Collections.singletonList(randomValue));
JedisUtil.returnResource(jedis);
}
} else {
log.info("丢弃死锁数据:{}", value);
}
}
}catch (Exception e){
log.info("--jdbcSink异常2---:{}", value);
log.error(e.getMessage(), e);
}
}
}
sink 代码:
DataStream<Row> loanUserDS = tableEnv.toChangelogStream(loanUserResult);
loanUserDS.addSink(new LocksJdbcSinkFunction(new JdbcOutputFormat<>(
new SimpleJdbcConnectionProvider(JdbcUtil.getDwdJdbcConnectionOptions()),
JdbcExecutionOptions.defaults(),
context ->
JdbcBatchStatementExecutor.simple(
"update dwd_order_detail set census_place_pro=?,census_place_area=? where id_card=? ",
(PreparedStatement ps, Row row) -> {
ps.setString(1, String.valueOf(row.getField(1)));
ps.setString(2, String.valueOf(row.getField(2)));
ps.setString(3, String.valueOf(row.getField(0)));
}, Function.identity()),
JdbcOutputFormat.RecordExtractor.identity())));
env.execute();